This post was authored by the Circom MPC research team.
Circom-MPC is a PSE Research project that enables the use of the Circom language to develop MPC applications. In this project, we envisioned MPC as a broader paradigm, where MPC serves as an umbrella for generic techniques such as Zero-Knowledge Proof, Garbled Circuit, Secret-Sharing, or Fully Homomorphic Encryption.
Throughout this research the team produced some valuable resources and insights, including:
- Implementation of circom-2-arithc, a fork of the Circom compiler that targets arithmetic circuits, which can be fed into any MPC backend
- Example integration of circom-2-arithc with the popular Secret-Sharing based backend MP-SPDZ in circom-MP-SPDZ.
- Proof of concept application using MPC-ML with keras-2-circom-MP-SPDZ which extends keras-2-circom-ZK to keras-2-circom-MPC.
- Modular Layer benchmarks for the keras model.
We decided to sunset the project for a few reasons:
- The overwhelming amount of effort to fully implement it.
- The low current traction of users (could be due to Circom). Hence a Typescript-MPC variant may be of more public interest.
- The existence of competitors such as Sharemind MPC into Carbyne Stack.
Therefore, we will leave it as a paradigm, and we hope that any interested party will pick it up and continue its development.
In what follows we explain:
- MPC as a Paradigm
- Our Circom-MPC framework
- Our patched Circomlib-ML and modular benchmark to have a taste of MPC-ML
MPC as a Paradigm
Secure Multiparty Computation (MPC), as it is defined, allows mutually distrustful parties to jointly compute a functionality while keeping the inputs of the participants private.

An MPC protocol can be either application-specific or generic:

While it is clear that Threshold Signature exemplifies application-specific MPC, one can think of generic MPC as an efficient MPC protocol for a Virtual Machine (VM) functionality that takes the joint function as a common program and the private inputs as parameters to the program and the secure execution of the program is within the said VM.
For readers who are familiar with Zero-Knowledge Proof (ZKP), MPC is a generalization of ZKP in which the MPC consists of two parties namely the Prover and the Verifier, where only the Prover has a secret input which is the witness.
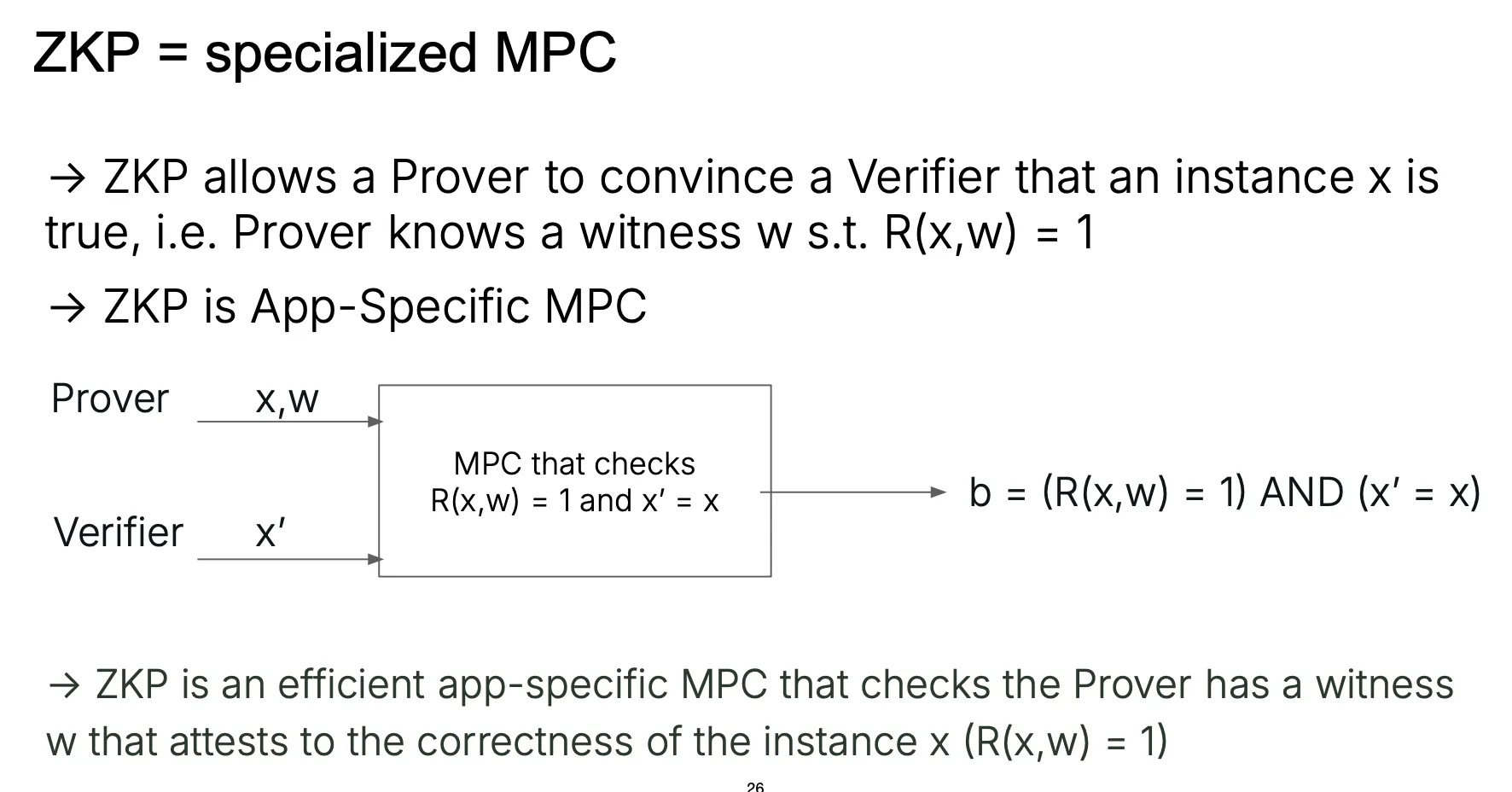
And yes, Fully Homomorphic Encryption (FHE) is among techniques (along side Garbled-Circuit and Secret-Sharing) that can be used for MPC construction in the most straightforward mental model:

Programmable MPC
That said, MPC is not a primitive but a collection of techniques aimed to achieve the above purpose. Efficient MPC protocols exist for specific functionalities from simple statistical aggregation such as mean aggregation (for ads), Private Set Intersection (PSI) to complex ones such as RAM (called Oblivious-RAM) and even Machine Learning (ML).
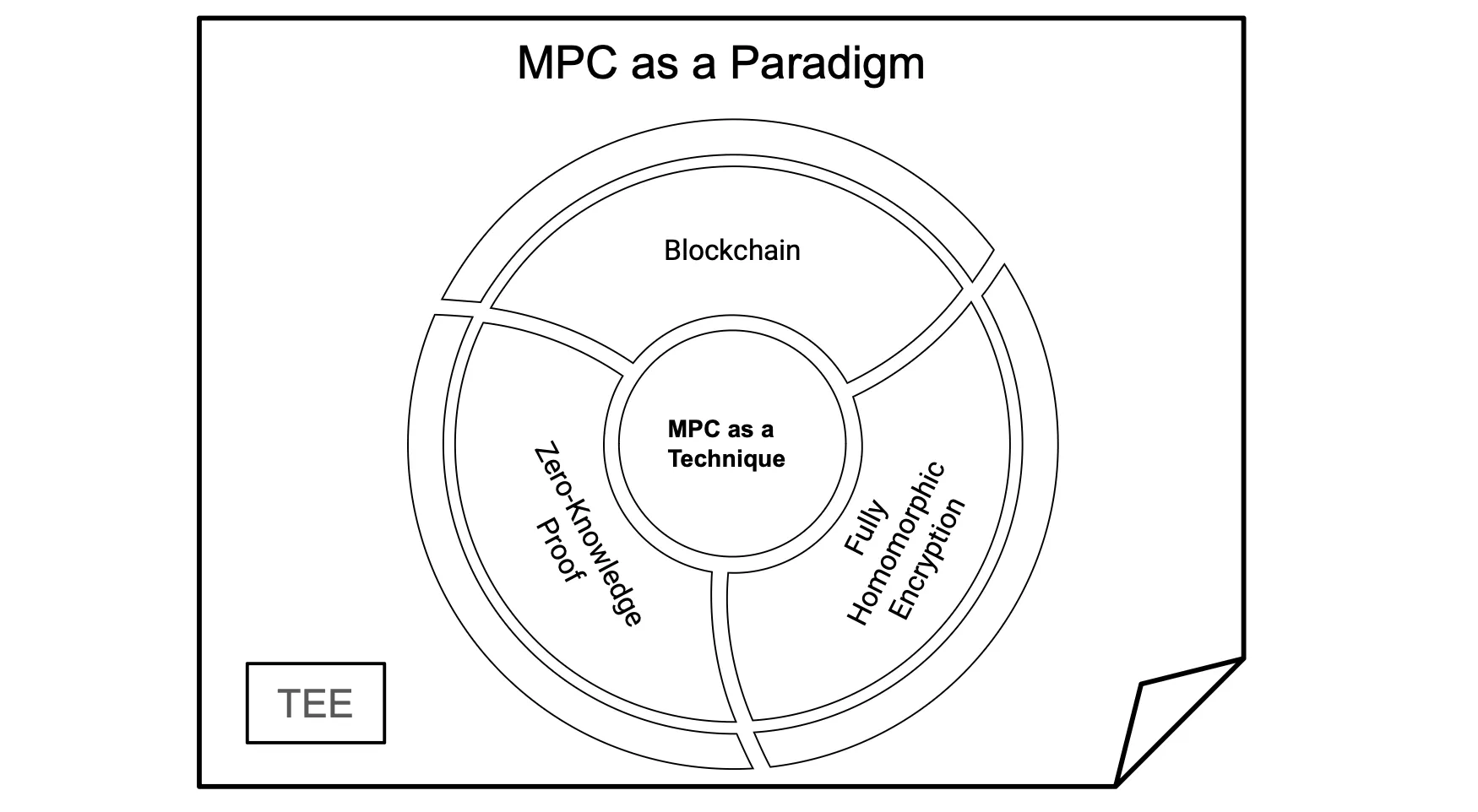
As each technique GC/SS/FHE and specialized MPC has its own advantage, it is typical to combine them into one's privacy preserving protocol for efficiency:

In what follows, we present work that enables the use of Circom as a front-end language for developing privacy-preserving systems, starting with the MP-SPDZ backend.
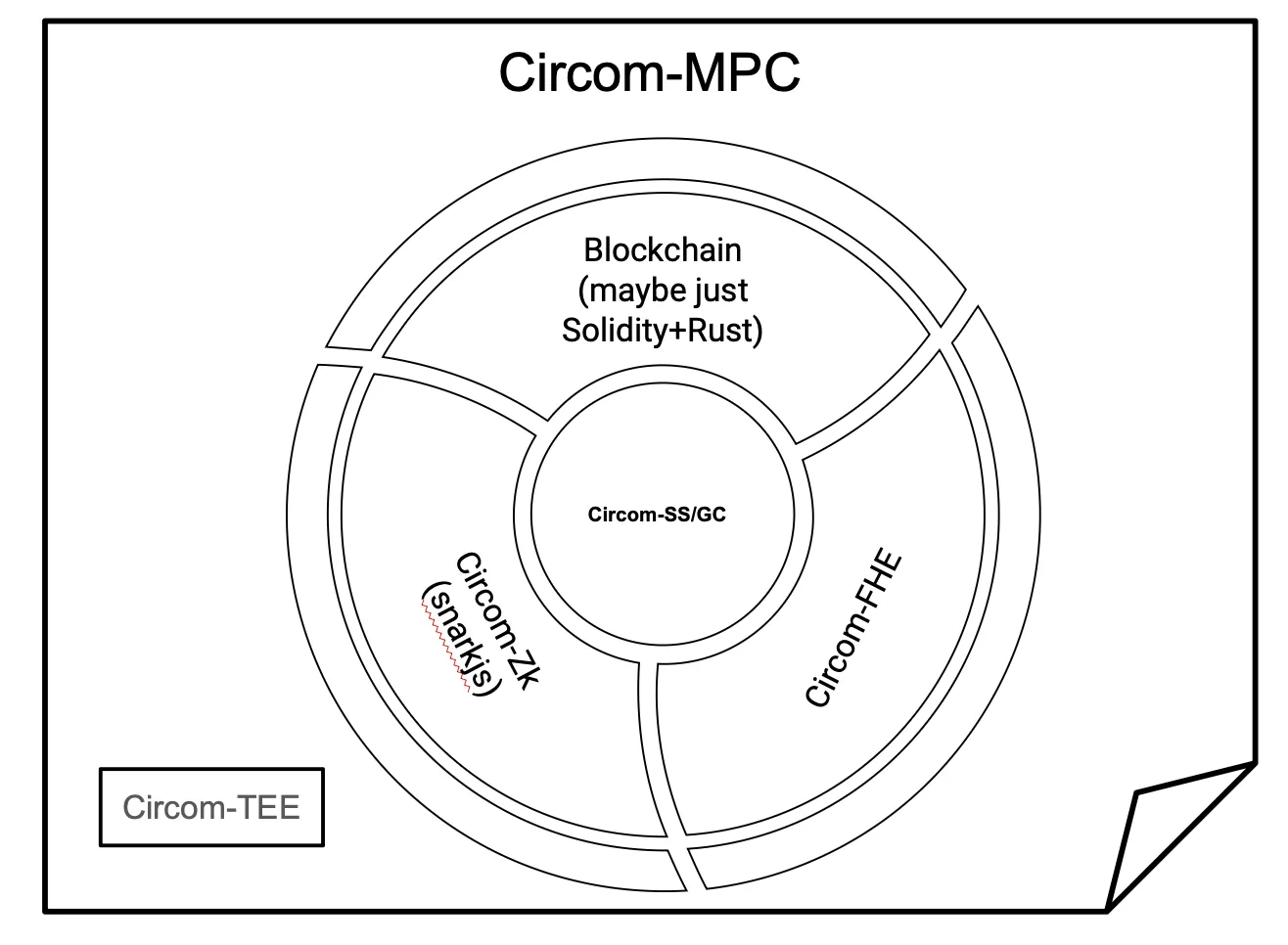
Detailed explanation of Progammable-MPC with Circom-MPC.
The Circom-MPC project aims to allow a developer to write a Circom program (a Circom circuit) and run it using an MPC backend.
The workflow
- A circom program (prog.circom and the included libraries such as circomlib or circomlib-ml) will be interpreted as an arithmetic circuit (a DAG of wires connected with nodes with an input layer and an output layer) using circom-2-arithc.
- A transpiler/builder, given the arithmetic circuit and the native capabilities of the MPC backend, translates a gate to a set of native gates so we can run the arithmetic circuit with the MPC backend.
Circom-MP-SPDZ
Circom-MP-SDPZ allows parties to perform Multi-Party Computation (MPC) by writing Circom code using the MP-SPDZ framework. Circom code is compiled into an arithmetic circuit and then translated gate by gate to the corresponding MP-SPDZ operators.
The Circom-MP-SDPZ workflow is described here.
Circomlib-ML Patches and Benchmarks
With MPC we can achieve privacy-preserving machine learning (PPML). This can be done easily by reusing circomlib-ml stack with Circom-MPC. We demonstrated PoC with ml_tests - a set of ML circuits (fork of circomlib-ml).
More info on ML Tests here.
Patches
Basic Circom ops on circuit signals
Circom-2-arithc enables direct usage of comparisons and division on signals. Hence the original Circom templates for comparisons or the division-to-multiplication trick are no longer needed, e.g.
- GreaterThan can be replaced with ">"
- IsPositive can be replaced with "> 0"
- x = d * q + r can be written as "q = x / d"
Scaling, Descaling and Quantized Aware Computation
Circomlib-ML "scaled" a float to int to maintain precision using :
-
for input , weight , and bias that are floats
-
, are scaled to and
-
is scaled to , due to in a layer we have computation in the form of the outputs of this layer is scaled with
-
To proceed to the next layer, we have to "descale" the outputs of the current layer by (int) dividing the outputs with
- say, with an output , we want to obtain s.t.
- so effectively in this case is our actual output
- in ZK and are provided as witness
- in MPC and have to be computed using division (expensive)
For efficiency we replace this type of scaling with bit shifting, i.e.
-
instead of () we do ()where is called the scaling factor
- The scaling is done prior to the MPC
- can be set accordingly to the bitwidth of the MPC protocol
-
now, descaling is simply truncation or right-shifting, which is a commonly supported and relatively cheap operation in MPC.
The "all inputs" Circom template
Some of the Circomlib-ML circuits have no "output" signals; we patched them to treat the outputs as 'output' signals.
The following circuits were changed:
- ArgMax, AveragePooling2D, BatchNormalization2D, Conv1D, Conv2D, Dense, DepthwiseConv2D, Flatten2D, GlobalAveragePooling2D, GlobalMaxPooling2D, LeakyReLU, MaxPooling2D, PointwiseConv2D, ReLU, Reshape2D, SeparableConv2D, UpSampling2D
Some templates (Zanh, ZeLU and Zigmoid) are "unpatchable" due to their complexity for MPC computation.
Keras2Circom Patches
keras2circom expects a convolutional NN;
We forked keras2circom and create a compatible version.
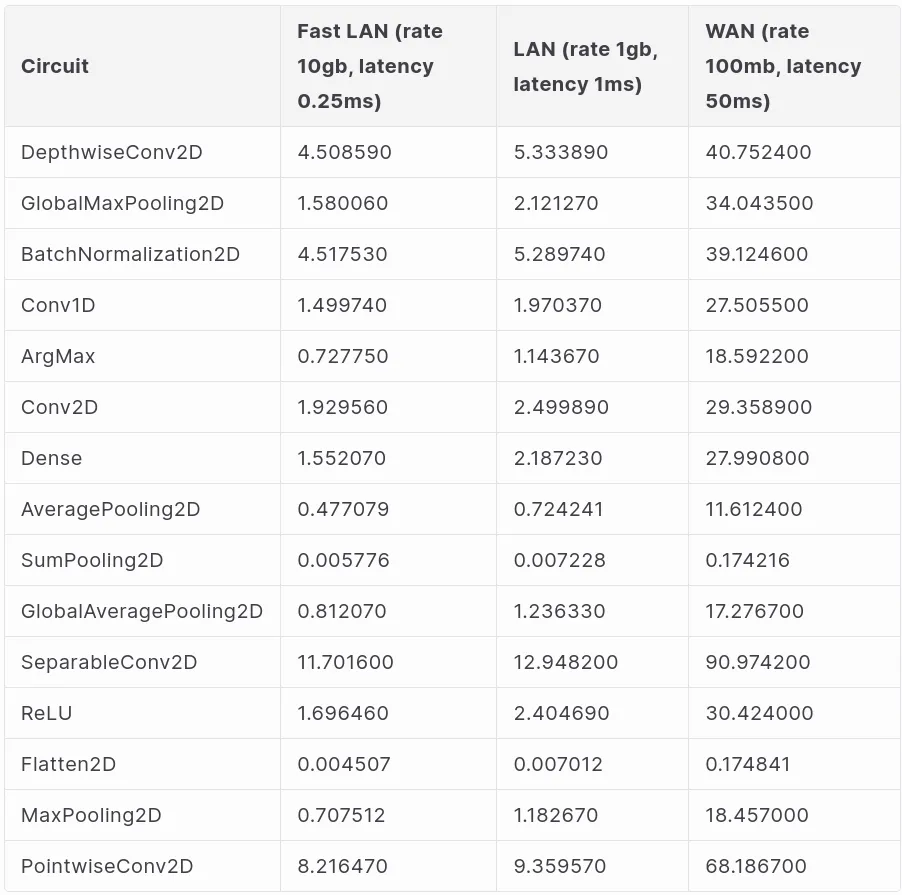
Benchmarks
After patching Circomlib-ML we can run the benchmark separately for each patched layer above.
Docker Settings and running MP-SPDZ on multiple machines
For all benchmarks we inject synthetic network latency inside a Docker container.
We have two settings with set latency & bandwidth:
- One region - Europe & Europe
- Different regions - Europe & US
We used tc to limit latency and set a bandwidth:
tc qdisc add dev eth0 root handle 1:0 netem delay 2ms tc qdisc add dev eth0 parent 1:1 handle 10:0 tbf rate 5gbit burst 200kb limit 20000kb
Here we set delay to 2ms & rate to 5gb to imitate a running within the same region (the commands will be applied automatically when you run the script).
There's a Dockerfile, as well as different benchmark scripts in the repo, so that it's easier to test & benchmark.
If you want to run these tests yourself:
1. Set up the python environment:
python3 -m venv .venv source .venv/bin/activate
2. Run a local benchmarking script:
python3 benchmark_script.py --tests-run=true
3. Build & Organize & Run Docker container:
docker build -t circom-mp-spdz . docker network create test-network docker run -it --rm --cap-add=NET_ADMIN --name=party1 --network test-network -p 3000:3000 -p 22:22 circom-mp-spdz
4. In the Docker container:
service ssh start
5. Run benchmarking script that imitates few machines:
python3 remote_benchmark.py --party1 127.0.0.1:3000
6. Deactivate venv
deactivate
Benchmarks
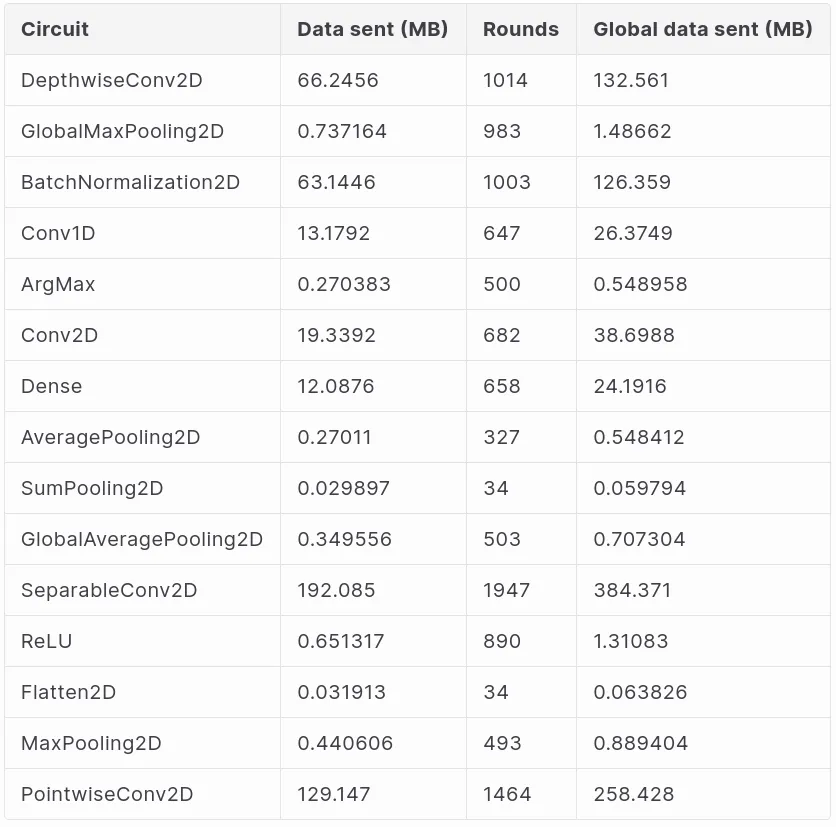
Below we provide benchmark for each different layer separately, a model that combines different layers will yield corresponding combined performance.
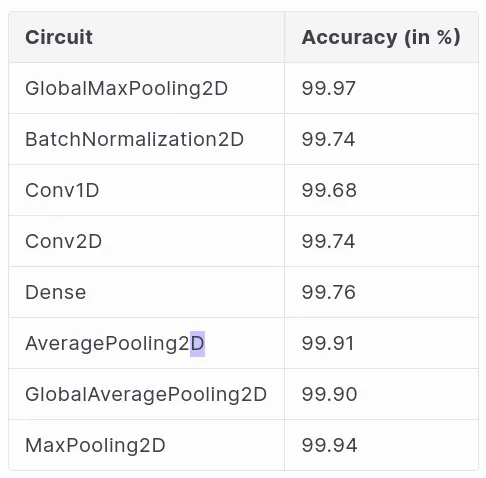
Accuracy of the circuits compared to Keras reference implementation:
Our above benchmark only gives a taste of how performance looks for MPC-ML; any interested party can understand approximate performance of a model that combines different layers.

